10s to 100ms; Optimising a Legacy Endpoint
This is the script for my first ever programming talk, delivered at the Tokyo Rubyist Meetup on April 15th, 2026. You can find a recording of the talk on Youtube (Github doesn't allow files over 1GB), and the slides (which you'll need if you want to see them) are here.
Introduction
Hi everyone, my name's Brett and unlike seemingly every other presenter I have not written a book, made contributions to Rails or used Ruby to write a presentation program I can use to deliver these slides from a Dreamcast. So what makes me qualified to give a talk here? Nothing really, which is kinda the point. I came to these meetups for a long time before I got a job at a 'tech' company and my favourite talk in all that time was a 10min presentation during a show & tell; an engineer at TableCheck (I think) going through how he'd solved a problem at work.
Seemingly pretty mundane but at the time I was the only technical person at a chain of eikaiwas, so hearing him talk about observability, performance monitoring and CI was incredible, like a whole new world. At that point my experience with CI was a bash script I'd written to run tests before deploying straight to the company AWS from my personal laptop (this one in fact, still going strong), and observability was mostly limited to me observing the site with my eyes.
So this talk is more or less for past me, and for the people still trying to break into the industry who're more interested in day to day life at a tech company than really cool stuff you can only do if you already have a stable job. For the more experienced devs in the audience, hopefully you'll enjoy hearing about the misadventures of a junior dev in a codebase you're not responsible for.
Part 1 - Precision Australian Engineering
Background
First some background. I work at Moneytree, which for those who don't know is a fintech company whose main value proposition is the ability to aggregate your financial data from all kinds of banks, point cards, credit cards and stock brokers. If you've heard of us (outside of as a place to work) it's probably in the context of our Personal Finance Management app, but for this story the relevant part of our business is the Vault, which we offer to client applications as a central UI for users (we call them 'guests') to connect and manage their various accounts. Vault's a React app which gets its data from our backend Rails monolith. It looks like this:

But, for the first 5-10 seconds after opening the page, you were more likely to see this:

Around the start of last year I joined a newly created Onboarding team, formed to address the fact we'd barely considered the onboarding journey of a Moneytree guest in something like 5 years. We took over responsibility for two web applications, and an SDK with versions on Android, iOS and web. All these projects had been distant background priorities of the three different teams responsible for them up until that point. There was no lack of technical debt to tackle. But first and foremost was this:
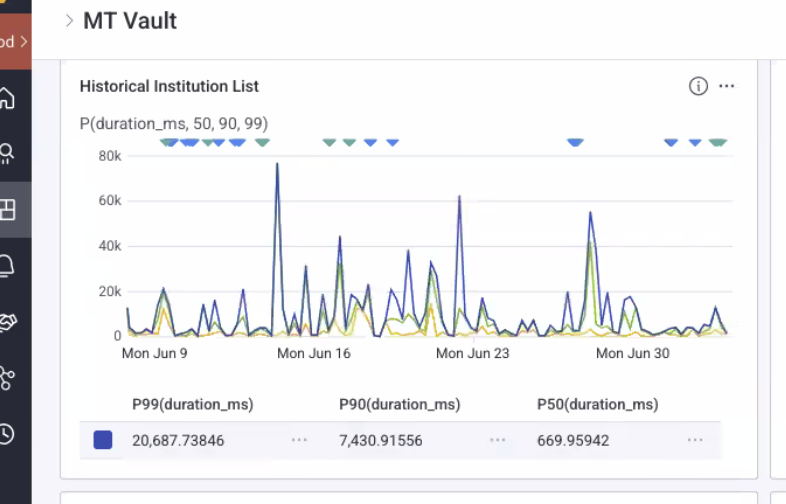
These are performance numbers for Vault's financial institution (FI for short) list endpoint. Guests cannot interact with the app until this response comes back and is parsed into local data stores. For those who aren't familiar with P99 etc., basically a P99 of 20 seconds means 1% of your users waited more than 20 seconds for a response. Fun fact, there's also at least one person who waited nearly 80 seconds for a response, well more likely they closed the tab and did something else because if you're staring at a (non-airline) loading spinner for anywhere near that long you'd assume the site is broken. You can also see that 10% of our guests waited more than 7 seconds. At 50% of guests we finally see something vaguely resembling acceptable performance at ~670ms.
Maybe this doesn't seem so bad, but we're not talking about tens of people here. You'll see later in the slides that this endpoint receives about 600 000 requests a month, so about 150 000 a week or 20 000-ish a day. 1% of that is still 200 people a day waiting more than 20 seconds for their page to load and 2 000 people waiting more than 7 seconds. Or more likely refreshing and triggering yet another request which takes multiple seconds to serve. I don't know about you guys but my attention span is not long enough to tolerate that, if I have to wait more than 5 seconds for a site to load that site does not exist. Google searches (an index of) the whole internet in milliseconds, my Youtube homepage loads in under 3 seconds, hell even Jira can load my time tracking faster than this. Surely I can manage to pack 2500 FIs into some JSON and send them off in under a second.
So how did I do it? For a 100x speedup like this you might assume I just chucked it in cache and called it a day, but that would be a pretty boring talk. Well, that's exactly what I did, eventually. But it's not the first thing I did. Oh no, I was on a new team and it was time to prove what a great engineer I was by coming up with the most perfect, clean, clever and optimised solution to make this endpoint run like a well-oiled machine.
That's a lot of JSON
There were a bunch of obvious problems, so naturally I didn't waste any time on trivial matters like profiling or inspecting the traces and dived right into fixing things. First of all, the endpoint lived in a controller used by a bunch of different applications which needed different data formats. This meant a bunch of extra code to run and attributes to add which Vault didn't care about at all, and I didn't want to have to worry about breaking as I made my changes. So I copied the whole action and its related code into a new, Vault specific controller and got to work.
A few small but obvious improvements came up as I dug into the existing code, like simplifying this:
def fetch_institutions
return head(:unauthorized) unless current_guest
country = params[:country]
return head(:bad_request) if country && !CountryService.supported?(country)
@service = PartnerInstitutionService.new(params[:client_id], current_guest) if params[:client_id]
if !@service
@institutions = current_guest.guest_institutions(@since_date, country)
elsif !@service.has_rules?
@institutions = current_guest.guest_institutions(@since_date, country)
else
@institutions = @service.institutions
end
# Each of these iterates over all 2500 FIs to change two attributes on the FIs passed to it
@institutions = hide_extra_institutions_for_multi_creds(@institutions, ['fi_name, another_fi_name'])
@institutions = hide_extra_institutions_for_multi_creds(@institutions, ['fi_name'])
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = hide_extra_institutions_for_multi_creds(@institutions, ['fi_name, another_fi_name'])
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = hide_extra_institutions_for_multi_creds(@institutions, ['fi_name'])
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = update_authorization_schema_for_multi_creds(@institutions, 'fi_name')
@institutions = update_authorization_schema_for_fi_name(@institutions)
end
def hide_extra_institutions_for_multi_creds(institutions, names_to_hide)
fis_to_hide = institutions.select { |i| names_to_hide.include?(i.name) }
# modify fis_to_hide in place & return the institutions array
end
Where each of those assignments to the @institutions instance variable iterates over the whole list of 2500 FIs to change 1 or 2 attributes on a single FI, then does it again on the next line.
def fetch_institutions(guest:, client_id:)
@service = PartnerInstitutionService.new(client_id, guest) if client_id
if !@service || !@service.has_rules?
institutions = guest.guest_institutions(nil, CountryService::JAPAN)
else
institutions = @service.institutions
end
non_legacy_institutions = institutions.where.not(locale_identifier: LEGACY_INSTITUTIONS)
legacy_institutions = Institution.where(locale_identifier: LEGACY_INSTITUTIONS)
legacy_institutions.each do |i|
i.is_active = false
i.status_reason = Institution::REASON_LEGACY
end
institutions + legacy_institutions
end
I simplified the method by extracting the response-related stuff to the controller action where it belongs, combining two redundant conditionals and extracting the multi_creds stuff to a different endpoint for reasons we'll get into soon.
There was also a small optimisation opportunity; fetching the FIs which needed hiding separately allowed a single loop over 6 FIs rather than 6 loops over 2500 FIs. That came with the tradeoff of merging two ActiveRecord::Relations though. Is that tradeoff worth it? Was the original implementation actually slow? Questions like this are why you should measure first, because I have no clue.
There were a few other similar changes, made more so I could understand what was happening than out of any real expectation of performance improvement since I hadn't yet addressed the elephant in the room.
Yep; 9MB of JSON is more than you'd ideally load before anyone can use your site. Rails has to construct and compress it, then send the result over what could be a 3G mobile connection before decompressing and parsing it on someone's 10 year old iPhone. This feels like a good time to remind you the performance numbers I showed earlier were just the time Rails took to send a response, not including network latency or slow client devices.
In addition to the issues inherent in sending that much data, it actually made our existing caching slower than an uncached request. Turns out JBuilder's caching doesn't cache the JSON output; instead it caches an intermediary ActiveRecord blob that's deserialized, passed to the template then re-serialized for the response. According to discussion on one of their Github issues it works best for small responses with heavy SQL queries associated; pretty much exactly the opposite of this. Since uncached responses were faster and the structure of the JSON was simple it was an easy call to ditch JBuilder in favour of using plain Ruby to construct the JSON.
That did nothing to decrease the size of the response though; for that I needed to dig through Vault's codebase and figure out which attributes we actually needed.
Necessary (12)
identity_keydisplay_namedisplay_name_readingtagsgroup_primarylocalized_status_reasonlogo_image_urlinstitution_typestatus_reasongroup_primary_keyis_active
Some stuff obviously had to stay, like id and entity_key so we knew which FI we were dealing with at a given time. Since the reason for loading all this data was to search it, we definitely needed attributes like display_name and logo_image_url to search for and display in results respectively. In the end there were 12 attributes per FI I definitely couldn't touch.
But since this was a legacy application, there were plenty I could kill with fire.
Unnecessary (11)
countryhidden: surprisingly unused, instead decided byis_activeandstatus_reasontheme_colorupdated_atcreated_atgroup_secondaryauth_schemas.creds_schema.certificate_fieldauth_schemas.client_requirementsauth_schemas.service_urlauth_schemas.unlock_urlauth_schemas.call_center_number
Stuff like country, which was sent as a request param and thus already used to filter on the backend, or call_center_number which probably made more sense in times when the only customer support available wasn't an LLM in a trenchcoat. Cutting these helped, but they still only got the JSON blob down to about 7MB. Luckily for me there was still one attribute with more nested inside it than the whole rest of the FI, and while it was absolutely necessary the timing was... flexible.
Unnecessary for search (28)
urladditional_informationauth_schemas_localized_descriptionauth_schemas- and 25 attributes nested under it, potentially x2
See search is the first thing a guest does in Vault, but it's not what they're there for. The end goal of finding an FI is to link it so we can aggregate their data, and doing that requires a whole bunch of information including OAuth URLs, connection guides and even more nested JSON containing schemas for the fields (and their validations) we need to collect in order to connect with an FI.
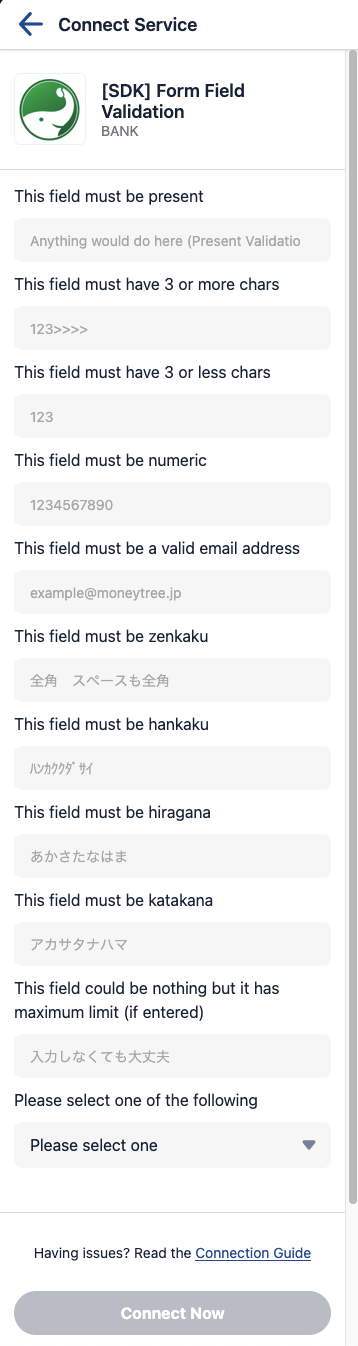
This is a somewhat extreme example but you get the idea, each of these inputs has a type, validation, maybe a max and min length, localized placeholder, localized label, the works.
On the other hand, absolutely none of this is needed to search the FIs. And somewhat unsurprisingly, most guests do not link all 2500 FIs we offer. So why does any interaction with our app rely on downloading the information they'd need to do that?
Promotion Time
After trimming all the other unnecessary attributes, authentication details accounted for twice as many attributes as the rest of the FI put together. So the cornerstone of my optimisation plan was extracting auth details from the list response to a separate, per FI details endpoint. Sure there would now be an extra request to worry about and some added frontend complexity, but cutting the response size by two thirds had to be worth it. Any extra delay to load the auth details when clicking a search result would be more than offset by not having to wait 2499 times that long on initial load.
Feeling good about my planned changes I wrote an investigation document detailing my findings and shared it with my team. I wrote an RFC based on that document and held a meeting to discuss it. I wrote a near-identical ADR and held a meeting to discuss that too, because back then (and for far too long after) I didn't realise RFCs and ADRs had more of a 'one or the other' relationship than a 'one to the other' pipeline.
This was it, this was what being a real engineer was all about. Taking on big problems, designing the perfect solution to them, deploying that solution to thunderous applause and promotions. The day came to roll it out, I hit merge and waited for the performance numbers to come rolling in. Later that week we had enough results to confidently reach a conclusion, and it was astonishing.
Now the eagle eyed among you may wonder if this is the same graph twice, and and you wonder correctly. I actually couldn't find a screenshot of the performance after my changes. Probably because I didn't want to think about it, much less memorialize it, but this gives you the general idea anyway. P99 was noticeably down but likely just a small sample size, P90 was a little lower but not in a statistically significant way and P50 had actually increased. My team, who interacted with Vault the most, said it felt subjectively much faster, but they probably just felt sorry for me.
In desperation I turned to the strategy I should've started with; actually measuring what was slow. I added telemetry spans for each step in preparing the response to get a concrete picture of what was still taking such a long time.
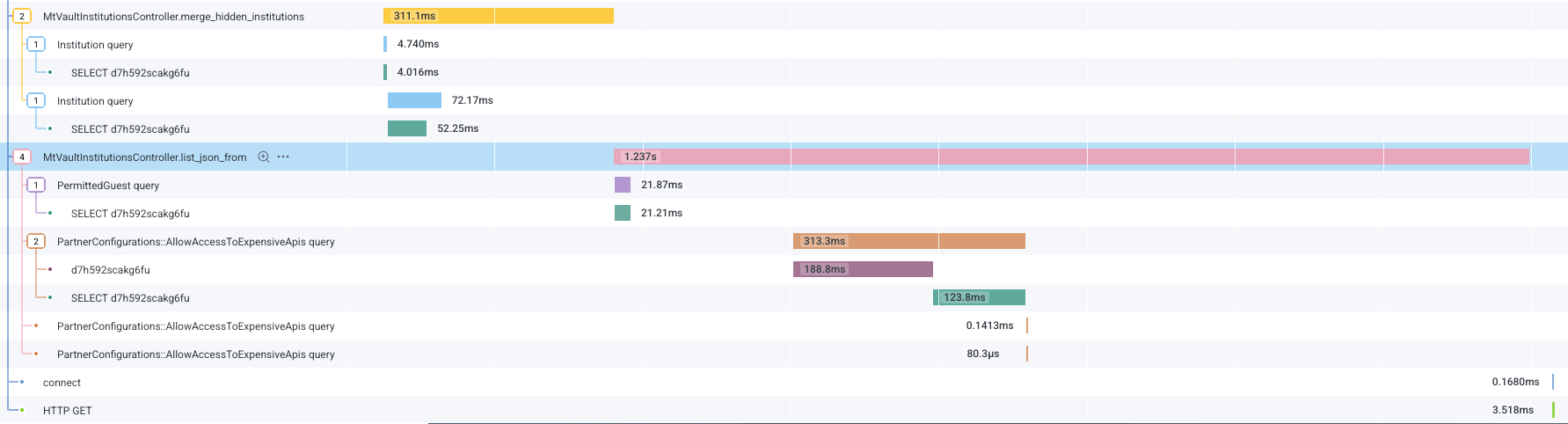
2 spans will immediately jump out at you; the one in the top left for merge_hidden_institutions and list_json_from in the center of the screen.
merge_hidden_institutions is part of what I showed you before, where we grabbed 6 FIs to be hidden in a separate query before merging them with the full list of FIs. You can see adding the smaller query isn't exactly a bottleneck, but merging the two ActiveRecord::Relations into an array apparently is since it takes 240ms of the total 311ms for that span.
list_json_from is the real culprit though, taking over a second just to build the JSON response (this trace was on the faster side, hence the relatively low overall numbers). You can see it checking if the guest has any special rules to see FIs they normally wouldn't, and taking a weirdly long time to check if the client application has permission to see expensive FIs.
But over half the remaining span is spent just building JSON. My first thought was to try the oj gem, which I'd seen recommended for faster JSON handling than the standard library, but it turned out we were already using it. Having already pared the contents of the response down to the bare minimum, seeing its size still causing the bottleneck was pretty demoralising.
But what if we didn't need to create the JSON each time? What if we could skip that, the ActiveRecord::Relation merging, the SQL queries and more or less everything else which took a relevant amount of time for all but the first guest every day? I'm talking, of course, about caching.
Part 2 - Just cache it
Maybe you think I'm crazy for not doing this from the start. After all who cares if the endpoint is slow once per day when, every request after that is fulfilled instantly? But there are good reasons companies don't just throw all their endpoints in cache by default. For starters, some endpoints are just not a good fit for caching. Imagine that every guest had their own customised rules on which FIs to show in Vault. Sure we could cache the response for them, but only for them. And due to its nature Vault is not something one guest opens multiple times a day, or even multiple times a month. We'd be burning space in our cache for no reason.
Speaking of space, looking at our Redis dashboard for the first time was the biggest wow moment I'd had since joining Moneytree.
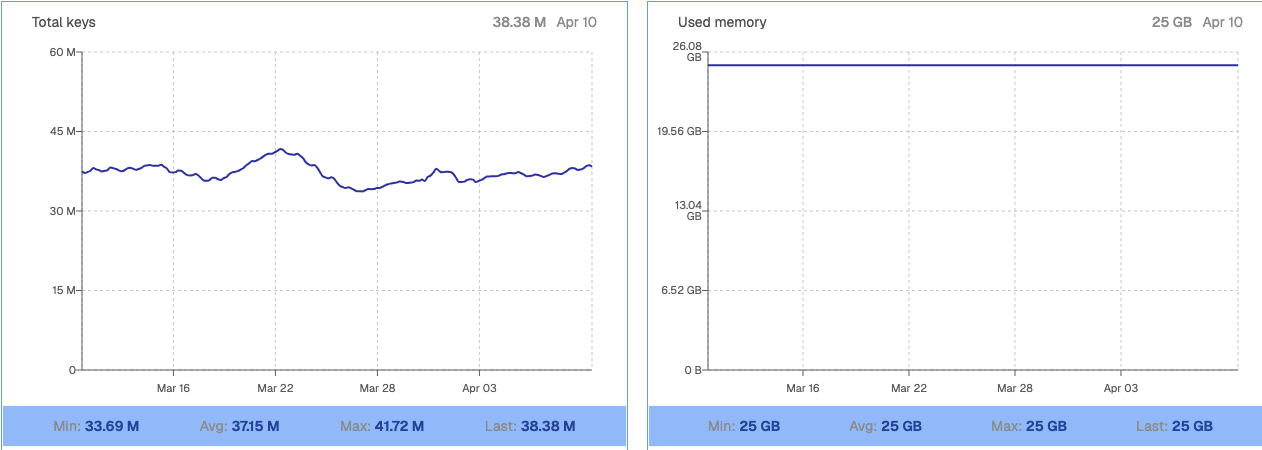
Yep that's 25GB of cache. Three times the RAM on this Macbook, and more than 25 times the size of the entire DB at my old eikaiwa job. And we use it all. That means if I mess up and shove a whole bunch of keys in there, they'll be evicting other teams' caches and causing degraded performance for their applications. That meant I had to minimize both the size of my cached value and the number of potential cache keys.
Code archaeology
I'd already made the JSON blob as small as possible, but the bottleneck still seemed to be constructing and serializing it. So I decided it'd be best to cache the whole response blob rather than individual fragments which would have to be deserialized, assembled, and reserialized for a response. It meant increasing the size of the cached value (about 1.5MB at this point) relative to caching fragments, but in return serving responses would be as simple as deciding the appropriate cache key and sending the raw cached JSON.
Of course this only worked if the possible responses could be reduced to a reasonable number of cache keys. I probably shouldn't say how many clients we have, but it's definitely enough that a 1.5MB JSON blob for each would occupy a noticeable chunk of our Redis storage. To figure out if my approach was viable I'd need to become intimately familiar with how responses could change depending on the combination of client and guest requesting them. This meant it was time for some real spelunking through the dark corners of the codebase.
One such corner lead me on the following journey:
- Each FI has a
localized_status_reasonattribute localized_status_reasonis assigned to the result ofcomputed_localized_status_reasoncomputed_localized_status_reasonis not a method on the controller or model- It's a global helper which takes the FI record and something called
contextas arguments
module InstitutionsHelper
def computed_localized_status_reason(institution, context)
return nil if computed_status_reason(institution, context).blank?
I18n.t("institution.status_reason.#{computed_status_reason(institution, context)}",
locale: locale)
end
def computed_status_reason(institution, context)
return nil if context.can_select_institution?(institution)
institution.status_reason || Institution::REASON_WONT_SUPPORT
end
end
- It calls another helper from the same file,
computed_status_reasonwith the same arguments, before interpolating the result into a localized string computed_status_reasonreturnsnilifcontext.can_select_institution?, otherwise it returns the FI's ownstatus_reasonproperty- So we're looking for what
context.can_select_institution?does; nothing else changes with the client making the request - Back in the controller,
contextcomes from a cached method calledrequest_contextwhich does this:
def request_context
@request_context ||= RequestContext.of({ requester: Requester.new(requester_uid || client_id),
guest: current_guest })
end
current_guestis a devise helper, so that just leavesRequestContext.ofandRequester.- To understand
RequestContext.ofwe need to understand its arguments, so we look forRequesterand find this
Requester = Struct.new(:client_id) do
def client_app_symbol
@client_app_symbol ||= OauthClientService.client_app(client_id)
end
def internal_client?
%i[internal1 internal2 internal3].include?(client_app_symbol)
end
def vault?
OauthClientService.application_sym(client_id) == :vault
end
end
- Okay it's just a struct with some convenience methods to determine who's making a request, let's move on to
RequestContext.of
module RequestContext
def self.of(data)
requester = data.fetch(:requester)
guest = data[:guest]
return GuestRequestContext.new(guest) if requester.nil? || requester.vault? || requester.internal_client?
ClientRequestContext.new(requester, guest)
end
def can_select_institution?(_institution)
raise NotImplementedError
end
end
RequestContextdoes have thecan_select_institution?method we're looking for, but it just raises aNotImplementedErrorofinstantiates aRequestContext, then uses theRequesterwe found above to decide whether it should return aGuestRequestContextorClientRequestContext- In the interests of time and sanity we'll only consider the
ClientRequestContextright now
ClientRequestContext = Struct.new(:requester, :guest) do
def can_select_institution?(institution)
@institution_ability ||= ClientInstitutionAbility.new(requester, guest)
@institution_ability.can?(:select, institution)
end
end
- It has a
can_select_institution?method! And it's actually implemented! - It instantiates an instance of
ClientInstitutionAbilitywith theRequesterand guest, then callscan?on that
module ClientInstitutionAbility
def can_select_institution?(institution, client:, guest:)
if institution.billing_group == 'expensive' &&
!Configuration::AllowAccessToExpensiveFIs.signed?(client.client_id)
return false
end
return true if institution_permitted_for?(institution, guest)
institution.is_active
end
end
- Finally, in
ClientInstitutionAbilitywe reach the actual logic. - It gives us a boolean, which filters alllll the way back up the chain to decide if an FI's
localized_status_reasonwill benilor a localized string based on itsstatus_reason.
If that sounded like the output of an LLM going in circles it's an accurate representation of how I felt. There can be very good reasons for complexity, but most of the classes, modules and helpers we just traversed only exist to forward us to the next one in the chain. At the end of the day, that whole journey resolves to:
- If the FI is expensive & the client can't link expensive FIs, return
false - If the guest has an explicit rule allowing access to the FI, return
true - Otherwise, return the value of the FI's
is_activeattribute
I'm as opposed to nested if statements as anyone else, but surely there was a way to handle that without requiring a multi-step journey across several files to understand it? Sure, this solution is probably more extensible in some ways. But the last time most of the files in that chain were touched was 5 years ago, and I left it untouched after my expedition.
The key to caching is...
After all that digging I ended up being pretty lucky; the vast majority of requests fell into 3 neat buckets:
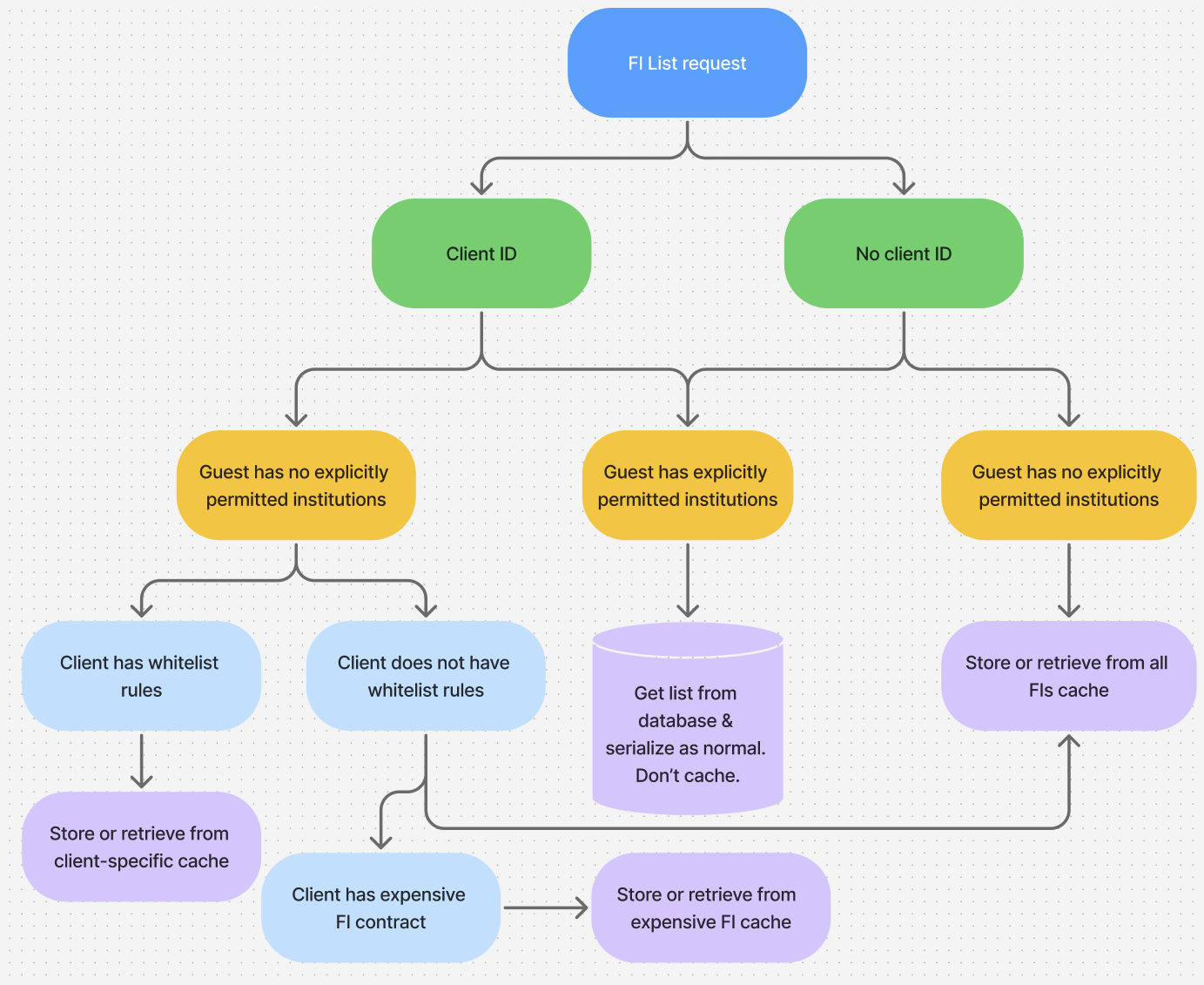
If there's no client ID or no specific whitelist rules for the client, they're served the global cache. Most clients don't have whitelist rules, so the majority of requests are served from here. If the client has whitelist rules only allowing a specific set of FIs, they get their own special cache, with just those FIs. And if they have expensive API permission they get the shared expensive API cache.
The only remaining case, which always hits the database, is where the guest has 'explicitly permitted institutions'. These are basically exceptions to the normal rules we apply for internal testing or external beta testers who help us out with testing our ability to aggregate new FIs. There are not a lot of these and most of them are probably internal test accounts no one uses anymore, so I wasn't too worried about not caching them.
With the buckets revealed all that was left was to create a module encapsulating everything caching related, from building the cache keys to constructing the response in cases where there wasn't already a cached value. All that was left in the controller as the interface was a single call to the Vault::InstitutionsCache module.
I read my fair share of programming blogs, so I'm familiar with the idea that the only two hard things in computer science are naming things and cache invalidation. With this in mind my caching module exposed helpers to clear the global, expensive FI and client caches individually, as well as a nuclear option to clear everything at once. I was confident I'd found all the places these would need to be triggered, like when an FI was created or updated, as well as when a client added whitelist rules or signed an expensive FI agreement. But just in case I also made rake tasks for each, so we could manually invalidate any of the caches if necessary. With backup plans in hand and telemetry prepared for cache use, performance and the number of cache keys, it was time to roll out my changes.
Please just don't break
My spirits were considerably lower as I prepared to hit merge this time. I had a revert PR ready to go and a terminal open for each cache invalidation rake task just waiting for me to hit enter. Success on this day looked like not causing an incident; actually improving the performance of the endpoint was secondary. With baited breath I hit merge, waited for CI and refreshed Vault. Then I refreshed it again, because someone has to warm the cache and all of two people regularly access our staging Vault.
Instant load, I didn't even have time to appreciate the loading skeleton I'd recently made to replace the dreaded spinner.
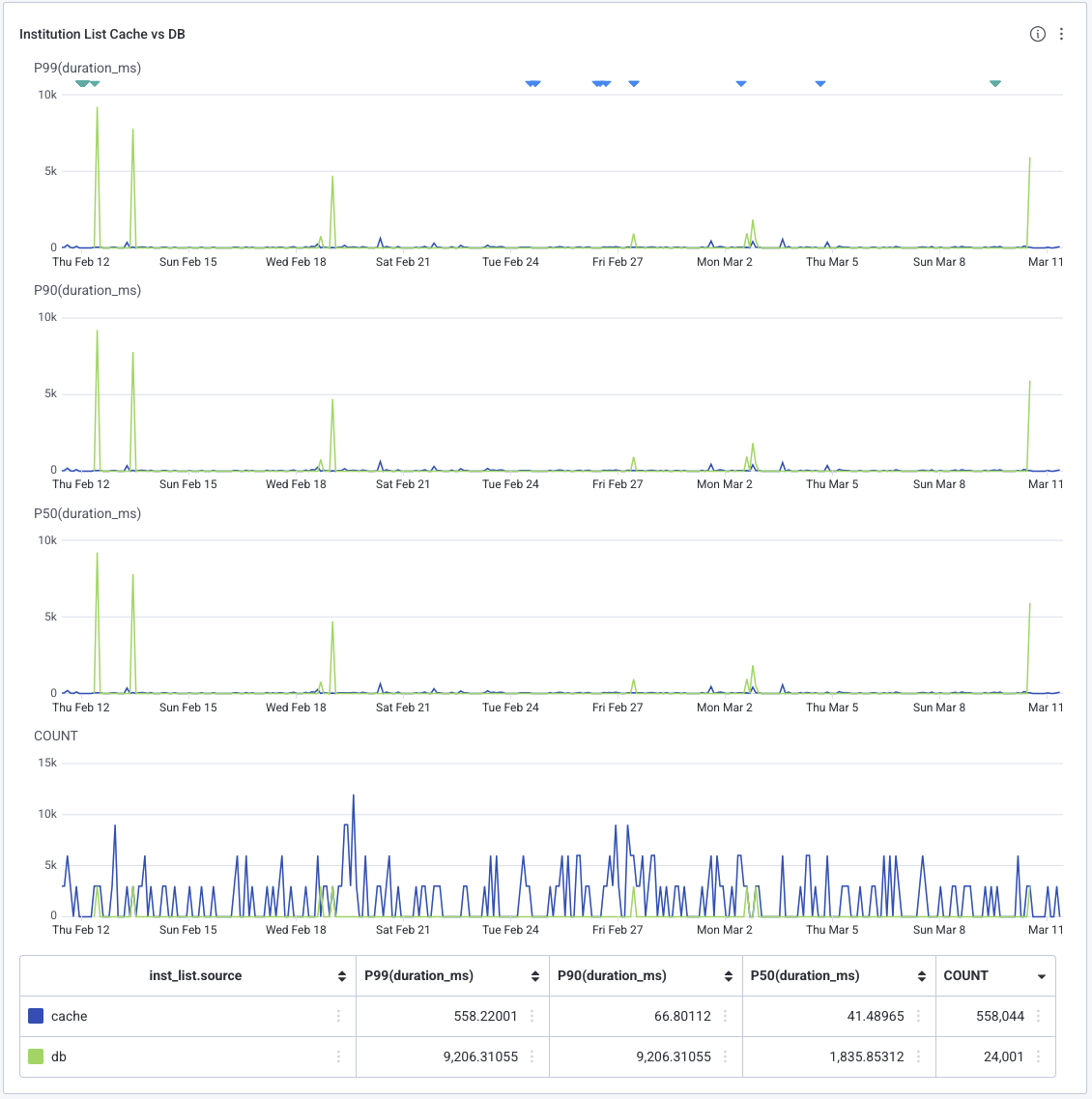
And much to my relief, the telemetry reflected that. This is a screenshot of a month's worth of traces from a random time a few weeks ago.
If we zoom into the summary you can see that, at least for cached responses, the P99 is now less than the original P50. Meanwhile the P90 and P50 are in genuinely fast territory, meaning the vast majority of our guests don't even notice Vault loading.
Of course someone still has to warm the cache, so one poor guest per bucket is sacrificed every day to the loading skeleton. That's still a few thousand guests per day who no longer have to stare at that damn spinner. The numbers aren't exact because of fairly aggressive sampling, but these days less than 4% of requests ever receive an uncached response.
So that's it, the end. Caching is pretty amazing huh? It makes responses faster, and it even made my talk faster. X minutes left and I'm all done, happily ever after, nothing else to talk about.
Any questions?
Praise for my technical genius?
Huh, what's that? Weird, the UI is in Japanese, but the FI names are in English.
Part 3 - The end?
In light of the screenshots you just saw, you might notice something missing from this flowchart. That's right, I forgot Japanese people speak Japanese. Well, not exactly. Fun fact, Moneytree used to exist in Australia! And most of our devs speak English. So all our applications are available in both English and Japanese.
I did know this, and I had a plan. To reduce the risk of an explosion of cache keys, I'd hardcoded the parameter controlling the language of the response to Japanese. I thought this ensured we'd always serve a Japanese list of FIs to actual customers, while devs would just have to put up with Japanese FI names for a while. Once we had some data on the number of cache keys generated in production I planned to either add a separate English cache or just refuse to cache any English requests, subjecting devs to our own failures in optimisation.
Unfortunately Rails had other plans, because buried deep in a rabbit hole (but also ApplicationController) was some code which overwrote the passed language value with whatever the guest's language value was set to. We have considerably more guests than devs who work on Vault, so for weeks everything seemed perfect. But one day we must have been unlucky enough for the cache to expire right before one of us logged into production Vault, warming the cache with a full list of English FIs.
Luckily it wasn't quite as bad as it could've been, our intrepid developer had been investigating a separate issue related to expensive FIs and thus had only contaminated the expensive FI cache with English, not the much more frequently used global cache. Once we'd figured out cache was the culprit, we cleared the expensive FI cache and quickly loaded Vault in Japanese before anyone else could do it in English.
Since at that point we were confident both that the number of cache keys was limited and most English language usage would fall into the global or Vault-specific cache, I went ahead and added separate en_ prefixed caches for each of the keys. To this day that caching logic remains untouched, instantly responding to thousands of requests per day. It was a long and bumpy road, but I'd finally done it.
The only two hard things...
What didn't remain untouched though was the cache invalidation logic. I didn't bring that up earlier for nothing. While I'd finally nailed down caching, invalidating that cache still had one nasty surprise in store.
Months after I thought I'd never look at the FI endpoint again, I started seeing spikes in the Honeycomb board I'd set up to monitor any increases in the time taken to create or update FIs. As you may remember, I'd added invalidation helpers to run on both those actions and had been worried they might cause small but noticeable increases in latency. Now I was seeing a few spikes, but only 20 seconds here, maybe 30 seconds there. Nothing to worry about really. I resolved to keep an eye on it and went on with my other work.
Before we get into just why that was a terrible idea, lets take a look at the cache invalidation code in question. Here are the methods as they stood at the time:
def clear_all
Rails.cache.delete_matched("#{LIST_CACHE_PREFIX}*")
end
def clear_for_client(client_id:)
Rails.cache.delete_matched("#{LIST_CACHE_PREFIX}#{client_id}*")
end
def clear_for_eab
Rails.cache.delete_matched("#{LIST_CACHE_PREFIX}eab*")
end
Nice and simple right, not much to go wrong. However I'd neglected to realise something very important.
If you run a similar WHERE foo LIKE prefix_ query over 25GB of postgres data you're laughing, especially if it's indexed. The thing about Redis though, is it's not postgres. Redis is a key/value store, basically a big hash, optimised for quickly retrieving the value of a single key. That's why GET is an O(1) operation, while KEYS (which delete_matched calls under the hood) is O(N) where N is the number of keys in the cache.
The number of keys in the cache.
The 25GB cache.
The 25GB cache with an average of 37 million keys.
Those spikes I mentioned earlier were spikes from nothing, because they were the only traces which made it through sampling. In reality, every single time an FI was updated it took 20 seconds to more than a minute to clear the relevant caches, sometimes even resulting in a 504 timeout. This could have gone on for ages, continuing to be only a minor annoyance to the affected team, if not for one key piece of information.
Our admin panel had a bulk update feature.
One day someone used that feature to bulk update 23 FIs, and oops it was suddenly impossible to update anything. The cache clearing operations were synchronous and the bulk update worked by queuing jobs to update each FI one by one, which... was a problem. The sometimes minute-plus cache clears caused the updates to time out before completing, causing the job to be rescheduled but not always releasing the lock which'd been taken out on the DB row. We saw a lock on one row which'd been active for hours, causing the job for that row to constantly be requeued and attempt the minute long cache clear.
One more fun bonus effect was the update jobs kicking off a rebuild & deploy of our public FI list every time they ran. This started a 10 minute long CI run to be started roughly once every 30 seconds, sometimes as often as once every 3 seconds.
Thankfully neither of these were incident-level problems since at least in the short term we could just not update FI data. So we disabled the API key allowing constant rebuilds of the FI website and I set about devising a way to clear the caches which didn't take minutes.
Here's what I came up with:
def clear_for_eab
Rails.cache.delete("#{LIST_CACHE_PREFIX}eab_ja")
Rails.cache.delete("#{LIST_CACHE_PREFIX}eab_en")
end
def clear_for_client(client_id:)
Rails.cache.delete("#{LIST_CACHE_PREFIX}#{client_id}_ja")
Rails.cache.delete("#{LIST_CACHE_PREFIX}#{client_id}_en")
end
def clear_all
clear_for_eab
Rails.cache.delete("#{LIST_CACHE_PREFIX}global_ja")
Rails.cache.delete("#{LIST_CACHE_PREFIX}global_en")
# This is actually faster than scanning the massive cache for a pattern
clients = OAuthApplication.pluck(:uid)
clients.each do |client_id|
clear_for_client(client_id:)
end
end
Since there are only two possible cache keys for the expensive FI cache I stopped playing code golf and just cleared each individually. 35 million iterations saved right there. Next was the client cache where much the same logic applied but with a client ID. Same for the global cache, and when clearing everything I remembered to use postgres for what it's good at (quickly getting lists of things) so I could use Redis for what it was good at (deleting values for single, specific keys). And with that I was really, finally, truly this time, done.
Part 4 - Takeaways
- Be very sure you included everything you need in your cache keys
- Including small details like the language of the response
- Write code your future self won't hate you for
- Writing extensible code is great, but is it really extensible if you need hours to understand it when you come back in 6 months?
- Measure first
- Or waste effort devising clever solutions for things that aren't actually problems
- Caching is pretty great when appropriate, despite the pitfalls
If I can have a brief shameless plug, I have blog where you can find a written version of this presentation and almost 0 other programming content other than weekly 'This Week I Learned' posts. If however, you're in the market for the opinions of some random guy on a random assortment of games and books, my blog is certainly one of the places for that.
Moneytree is unfortunately not hiring developers right now, but if you know any designers or HR/Sales people please feel free to send them our way.